Universell utforming av PDF - Kunnskapsbasen
Universell utforming av PDF
PDF er fil som vises på skjerm I akkurat same form som om det hadde vært skrevet ut. Det er en form for digitalt papir.
Innholdsfortegnelse [-]
English version: Universal Design of PDFs
PDF er en av det mest brukt type læringsressurser. Mange undervisere laster opp artikler, utdrager, lysbilder, og oppgaver som PDF i Blackboard til studentene sine. Det er viktig at disse PDFer er tilgjengelig for alle studenter. De må være lesbare for, blant annet, tekst-til-taletjenester og for studenter som leser på skjerm og trenger å navigere seg rundt dokumentet.
En OCR-behandlet PDF er nok for at tekst-til-taletjenester og skjermlesere kan lese det.
Konvertering fra Office 365 til PDF
Med en god grunndokument kan man enkelt lage en universell utformet PDF. Word eller PowerPoint dokumenter som blir konverterte til PDF må være unversell utformet for at PDFen blir det. For at en PDF skal være universelt utformet må det ha ha riktige tagger. Taggene forteller tilgjengeliggjørende tjenester hvordan de skal lese filen. For eksempel tittelen, om det er kapitler eller seksjoner og hvilket språk PDFen er på. Det er mange tjenester som lager PDFer. Flere at gratis versjonene som finnes på nett setter ikke opp taggene riktig. Vi anbefaler at man bruker Adobe Acrobat Pro for mest universell utformet resultater.
I Office 365 programmer som Word og PowerPoint man kan automatiske konvertere dokumenter eller presentasjoner til Adobe PDF. Alle på NTNU har tilgang Adobe produkter og du kan lese hvordan å få laste ned Adobe produkter her.
Se våre veiledere på hvordan å lage universell utformet Word-dokumenter og PowerPoints.
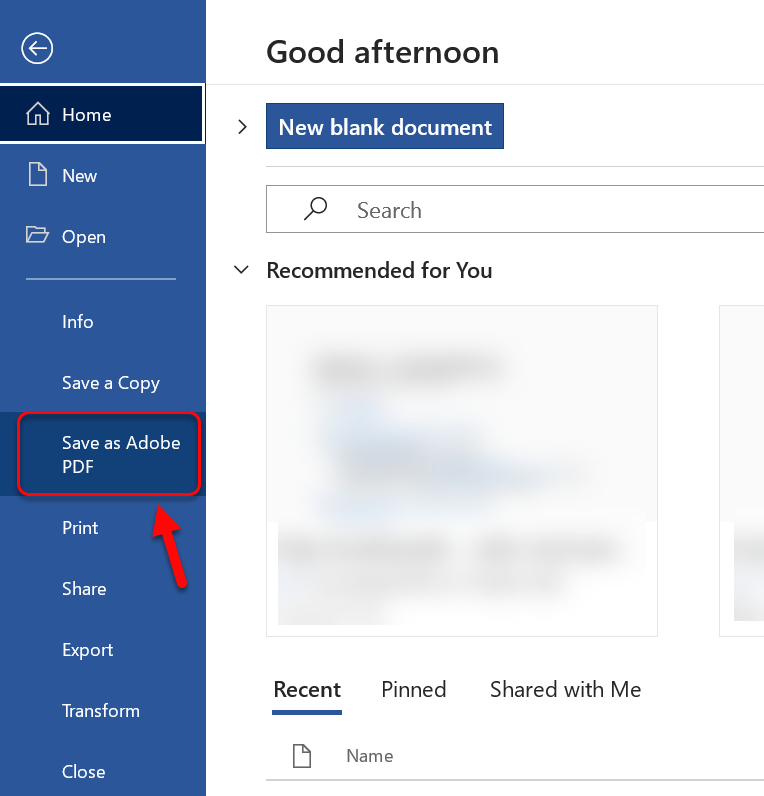
For å lage en fil som PDF i Word, PowerPoint eller andre Office 365 programmer kan man klikke først på «Fil» og så velge å «Lage som Adobe PDF». Da blir filen lagre som en PDF med riktige tagger.

Scanning fra papir til PDF
Mange legger ut scannet artikler og bokutdrag til sine studenter i Blackboard. Disse er ofte lagt ut som PDF. Hvis kopikvalitenet er ikke bra kan dere risikere at det er umulig for PDFene å leses med tekstgjenkjenningstjenester og at de derfor blir utilgjengelig.
Papiret som er skannet inn består i utgangspunktet kun av et stort bilde. Et bilde av tekst er ikke mulig å lese for dem som bruker en skjermleser, og for dem som må forstørre opp innholdet. For at alle brukere skal kunne forstå innholdet, må teksten konverteres fra bilde til vanlig tekst.
Dokumenter som skannes inn ofte blir uskarpe. Kanskje ligger dokumentet skrått, eller det har blitt skannet og kopiert opp i flere runder, slik at det blir vanskelig å lese for alle brukere. Det blir også umulig å gjøre søk og kopiere deler av innholdet, så lenge det er i form av et bilde.
Konverter fra bilde til tekst
Du konverterer fra bilde til tekst ved hjelp av et eget OCR-program (Optical Character Recognition) som ofte følger med skanneren, eller med OCR-funksjon i Adobe Acrobat Pro. Merk at uavhengig av om du bruker Acrobat Pro eller et annet program med OCR-funksjon, så trenger du Adobe Acrobat Pro for å kunne gjøre dokumentet fullt ut universelt utformet. Alle på NTNU har tilgang til Adobe pro versjoner.
Kvaliteten på den optiske bokstavgjenkjenningen avhenger av mange faktorer, blant annet bildekvaliteten og skrifttypen. Når du har brukt OCR-funksjonen, må du derfor først sjekke at resultatet ble riktig.
Struktur
Det er også viktig å sørge for at innholdet får riktig struktur. Det vil si at for eksempel overskrifter presenteres som overskrifter, slik at brukere som bruker hjelpemidler kan navigere i og lese teksten. Du lager rett struktur ved å bruke tagger. Det finnes ulike veiledninger og verktøy i Adobe Acrobat Pro (Adobe) som hjelper deg slik at tagg-strukturen blir bra.
Hvordan scanner og OCR-behandle utdrag med Adobe Acrobat Pro
Adobe har veldig gode og detaljert ressureser om hvordan å sikre god tilgjengelighet. Bruk gjerne deres instruks på hvordan opprette og bekrefte PDF-tilgjengelighet. Det som følger her er en enkelt versjon som sikre at PDF'ene oppfyller kravene.
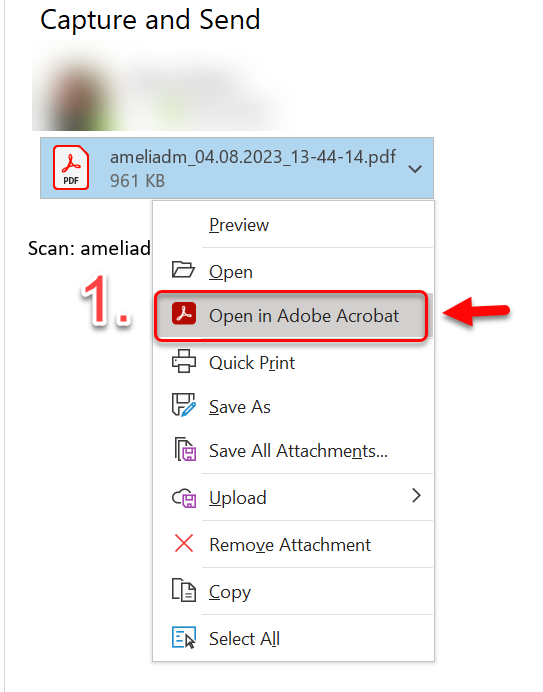
- Når du har dokumentet åpne det i Adobe Acrobat.

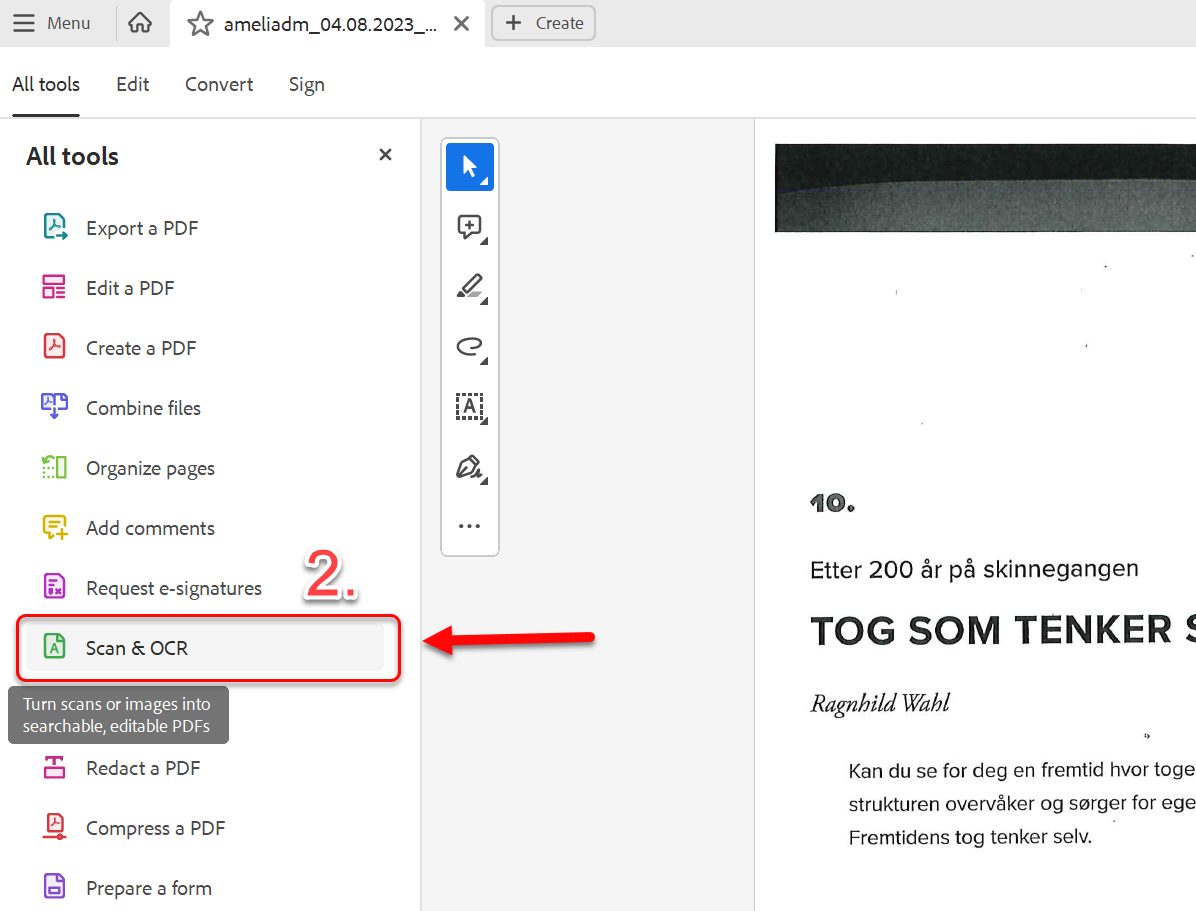
- Når Acrobat åpnes, velg "scan & OCR" fra meny (avhengig av Adobe-versjon du har kan menyen være på venstre eller høyresiden).

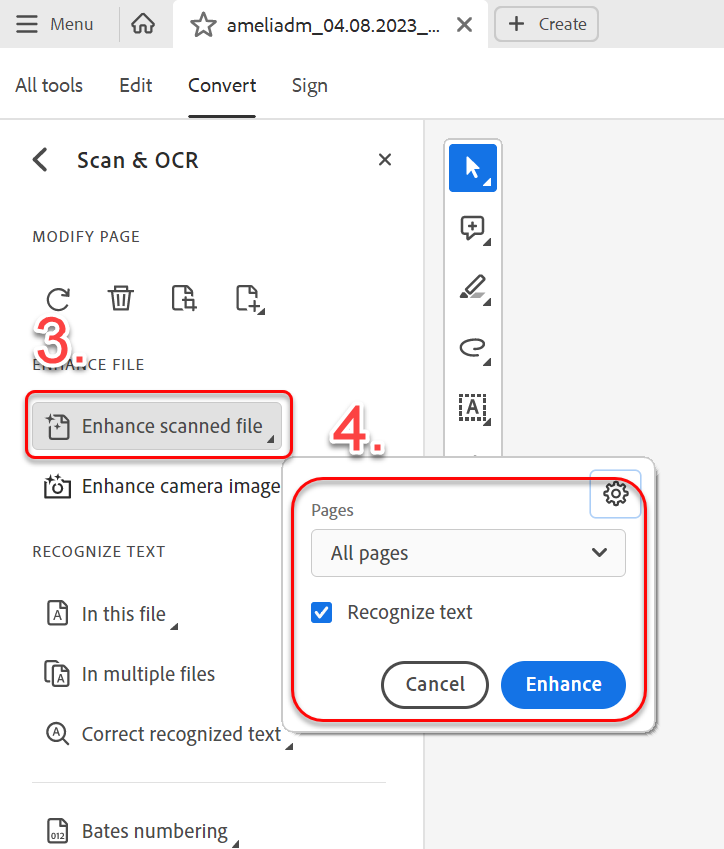
- Velg deretter "enhance scanned file" og passer på at "recognize text" er valgt før du klikker på "enhance"

- Etter det er dokumentet OCR-behandlet.
- Du kan se om dokumentet er OCR-behandlet ved å se om det er mulig å highlight tekst i PDF'en.
Avansert tilgjengelighet av PDF i Adobe
Det er også mulig - og anbefalt - å sjekke tagger og leserekkefølgen av PDFen. Vi anbefaler at du bruker Adobes veiledere som støtte her.
PDF som får lav score i Ally
Denne nano-kurs forklarer noen av årsaker til at feil-konverterte PDF kan få dårlig score i Ally i Blackboard. PDF-filer opprettet fra ulike programmer gir ofte lav score av Ally.
Kompendiumstjenesten fra Universitetsbiblioteket
UB kan lage tilgjengelig og fullt universell utformet kompendier for emner. Les om hvordan å inkludere trykte bokutdrag og artikler i pensum. De lager tilgjengelig PDF av artikler og utdrag for deg.
Se også
NTNU sider om universell utforming:
- Universell utforming av digitale læringsressurser
- Universell utforming av videoer
- Universell utforming av presentasjoner og lysbilder
- Blackboard Ally
Uutilsynet og universell har veiledere om universell utforming av PDF som kan være nyttig å lese.
- Universell utforming av PDF-dokumenter(Universell, esktern lenke)
- Løsningsforslag for nettsider: PDF (uutilsynet, ekstern lenke)
Kontakt
Ta kontakt med Seksjon for læringstøtte (SLS) for hjelp med digital læring. Ta kontakt via NTNU Hjelp.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}