Omnom undervisningsopptak - Kunnskapsbasen
Omnom undervisningsopptak
På Gjøvik fantes en gang systemet omnom, som ble benyttet til automatisk opptak og strømming av undervisning fra klasserom og auditorier. Systemet var basert på selvbetjening og automatisering. Systemet er nå nedlagt til fordel for Panopto.
Dette er nå en minneside, og inneholder en tekst som opprinnelig var publisert på IT-tjenesten ved Høgskolen i Gjøvik sin blogg.
![]()
Temaside om nettbasert undervising
Innholdsfortegnelse [-]
Merk: Det systemet som beskrives her er ikke lenger tilgjengelig. Dette er historie.
Problemstillingen
IT-tjenesten ved Høgskolen i Gjøvik hadde en klar strategi om å bruke åpen programvare overalt der det var mulig, og å støtte PC-plattformene Windows, Mac og Linux. Der det ikke fantes åpen programvare som gjorde jobben prøvde vi å løse oppgavene ved å tilpasse eksisterende løsninger eller utvikle programvare selv. Kun unntaksvis gikk vi til innkjøp av «hyllevare».
Vi hadde lang tradisjon for å utvikle egen programvare. Vi laget vår egen FEIDE-løsning, infoskjerm-systemet «Kitteh», et webgrensesnitt for visning av Exchange-kalendere som vi har kalt «WIHN», som i sin tur var en erstatning for det gamle kalender-systemet «HEVN» (som også var utviklet ved HiG). Som man ser hadde vi også en viss tradisjon for rare navn på prosjektene våre. Så da kommer vi til «omnom».
Til høstsemesteret 2011 var det behov for å få opp en løsning for opptak av auditorie-forelesninger, slik at fjernstudenter kunne følge enkelte fag uten å måtte dra i forelesninger på HiG. Vi begynte å undersøke hvilke produkter som var tilgjengelig i markedet, og hadde møter med mange leverandører som kunne tilby løsninger fra Tandberg (Tandberg Content Server) og Sony (Mediasite). Det vi så var at disse løsningene ikke var utviklet med tanke på utdanningssektoren, og var avhengig av veldig mye manuelt vedlikehold og tilpasninger. I tillegg gjorde prisen på disse løsningene at vi ble nødt til å se på andre løsninger.
Matterhorn
Et produkt vi hadde fulgt med på en stund var prosjektet Matterhorn, et åpent kildekode-prosjekt utviklet av en rekke universiteter og utdanningsinstitusjoner over hele verden (prosjektet har siden byttet navn til Opencast). Siden det var utviklet av og for universiteter var Matterhorn mye bedre tilpasset våre behov i forhold til opptak av prosjektørbilde samtidig med kamera, samt avspilling og indeksering av opptakene i etterkant. Ulempen var at vi ville bli nødt til å gjøre hele jobben med oppsett, tilpasning og vedlikehold helt selv, men det ble vurdert at dette var et bedre alternativ enn de store kostnadene for et ferdig system, som uansett ville ha krevd en viss innsats fra vår side. En annen ulempe var at det var knapt med tid for å ha systemet klart.
Det nødvendige utstyret for å sette opp Matterhorn ble bestilt på tampen av vårsemesteret 2011, og prosjekt med å sette systemet i drift startet ved semesterslutt. Det viste seg fort at installasjon av Matterhorn var en komplisert affære, med mange innfløkte avhengigheter til ulike eksterne biblioteker og verktøy. Matterhorn i seg selv er et stort java-basert prosjekt med en mengde moduler som skal jobbe sammen. Samtidig var dokumentasjonen mangelfull og utdatert; det måtte en del prøving og feiling til for å installere grunnsystemet, og ukene gikk. Sommerferieavvikling ble utsatt for å få tid til å gjøre systemet ferdig.

Ved studiestart våren 2011 var systemet med nød og neppe klart til bruk, men det hadde ikke blitt tid til veldig mye testing. Det oppsto umiddelbart mystiske problemer med opptak som ikke ble fullført skikkelig, opptak som ikke ble publisert skikkelig og opptak som ikke ville starte i det hele tatt. På grunn av den dårlige dokumentasjonen og den store kompleksiteten i Matterhorn var det vanskelig å feilsøke problemer, og manuell disaster recovery var umulig: hvis et opptak feilet i etterbehandlingen var det ingen mulighet for å begynne etterbehandlingen på nytt.
Det viste seg også at store deler av det man måtte forvente av muligheter for sletting, flytting og redigering av opptak manglet fullstendig fra løsningen, Matterhorn fremsto som et uferdig produkt (dette var i versjon 1.1). Problemene vedvarte flere uker inn i semesteret, og det ble klart at noe måtte gjøres.
Skal du gjøre noe riktig må du gjøre det selv
Etter flere måneders arbeid med å sette opp og jobbe med Matterhorn hadde vi et klart bilde av hva som måtte være på plass for å ha en opptaksløsning som passet for HiG, og vi hadde også en liste med ting vi mente Matterhorn løste på en dårlig måte, eller ikke i det hele tatt. En kort kravspesifikasjon ble satt opp, basert på hva vi ønsket oss, hva vi mente ville være oppnåelig, og hva som kunne komme raskt på plass hvis vi gjorde jobben selv. Systemet vi ønsket oss måtte oppfylle følgende krav:
- Enkelt for forelesere å planlegge opptak eller streaming
- Helautomatisert start, stopp og publisering (etter opptaksjobb er registrert)
- Mulighet for disaster recovery (redde ut opptak hvor opptaksjobben sviktet i et eller annet ledd, som skjedde ofte)
- Støtte opptak og livestreaming, helst samtidig
- Lav kompleksitet - Keep It Simple, Stupid - bruke eksisterende UNIX-komponenter der dette var mulig
- Bruke moderne kodeker (h264)
- Støtte avspilling på Windows, Mac, Linux og mobile enheter
- Gjenbruk av maskinvaren som opprinnelig ble kjøpt inn til Matterhorn
Et utviklingsteam på fire ble satt opp, og fire arbeidsområder ble definert:
- Registrering av opptaksjobber (frontend)
- Behandling av opptaksjobber (backend)
- Opptak/streaming (backend)
- Avspilling (frontend)
Samtidig gjorde vi i begynnelsen en del teknologivalg med tanke på å holde kompleksiteten lav: NFS for filoverføring fra opptaksklienter til server (Matterhorn brukte et REST-interface), filbasert jobbhåndtering og lagring av metadata (ingen databaser eller XML), cron for scheduling (ingen kontinuerlig kjørende daemons), minimalt med konfigurasjon og integrering.
Prosjektet ble døpt «omnom», inspirert av det klassiske backronymet «UNIX»: «OMnom is NOt Matterhorn», og i tråd med tidligere navnevalg. Vi ga oss selv tre uker på å fullføre prosjektet. Tidsskjemaet sprakk, men ikke med mye, og i begynnelsen av november 2011 ble det første opptaket gjort med det nye omnom-systemet.
Opptaksboksene
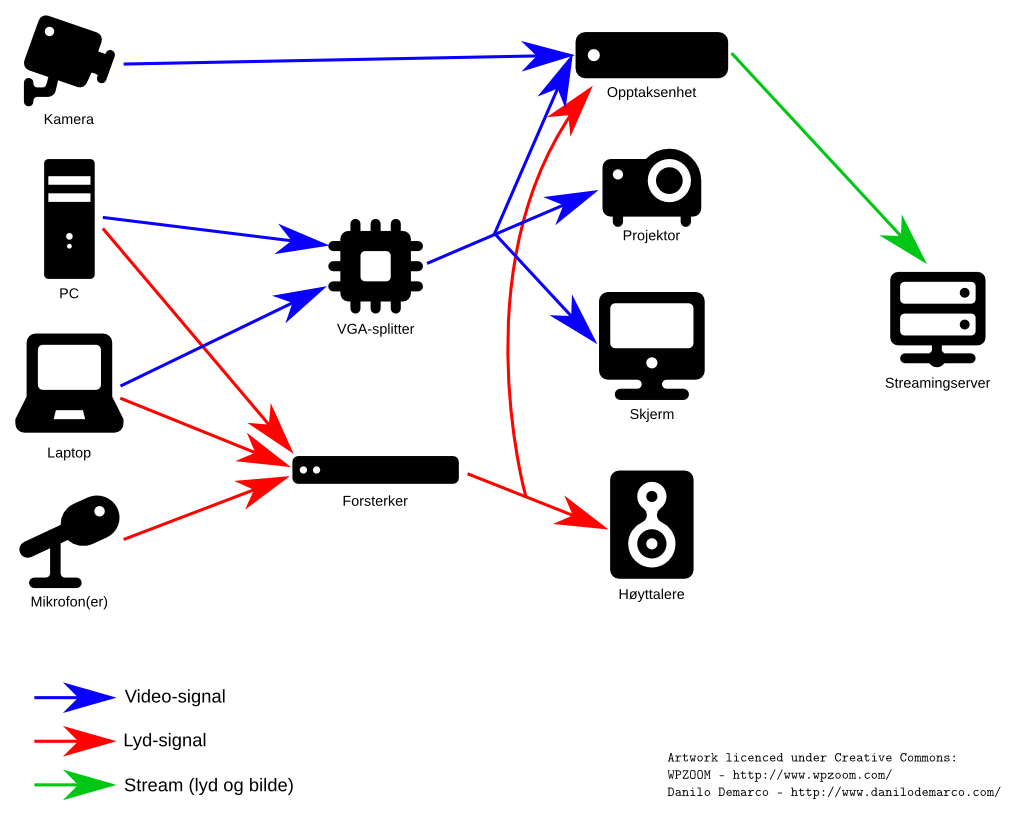
Selve kjernen i Omnom er de såkalte opptaksenhetene, som i bunn og grunn er helt vanlige datamaskiner med noen ekstra utvidelseskort og spesialtilpasset programvare. Det er et videokort for å ta inn et kompositt-videosignal for kameraet, og et kort som tar inn VGA-signal og gjør det tilgjengelig som en video-enhet på maskinen (akkurat som et kamera). I tillegg benyttes det innebygde lydkortet for å ta inn lydsignalet. Vi ender dermed opp med tre inn-enheter:
- Kamera-bilde (montert på vegg, vendt mot tavle eller podie)
- VGA-bilde (som henter nøyaktig samme bilde som det som vises på projektor)
- Lyd (som er nøyaktig samme lyd som det man hører over høyttalerne i auditoriet)
For å få til dette må de ulike signalene tappes eller splittes med omhu. Her er et diagram som viser hvordan signalene flyter:

Alt en foreleser trenger å gjøre når en forelesning skal starte er å starte på riktig tidspunkt og sørge for å bruke mikrofon (hvis det er lyd i rommet blir det lyd i opptaket).
Omnoms oppbygning – en teknisk gjennomgang
I grove trekk fungerer Omnom-systemet slik:
Når en bruker ønsker å gjøre et opptak eller en strømming logger man inn til planleggingsverktøyet. Her har vi fokusert på å gjøre jobben så enkel som mulig, med ingen unødvendige valgmuligheter eller kompliserte dialoger.
Systemet lister automatisk opp alle registrerte fag ved HiG, så man kan velge dette fra en liste i stedet for å skrive det inn manuelt. Det samme gjelder ansatt-opplisting for forelesere. Dette minimerer risiko for skrivefeil, og gjør det enklere å grubbere og katalogisere i etterkant. Det er også i dette steget vi ber om metadata, slik at et opptak har dette klart så fort som overhodet mulig.

En opptaks- eller strømmings-jobb blir i backend definert i en fil med filbenevnelsen .nom, på følgende format:
k105-8f22d2f3b295.nom: start|1378282380 duration|110 captureagent|k105 inputs|both outputs|both lecturer|klausb topic|SMF1301F title|Bedrifts- og forretningssystemer -Nr4 description| started|0 ended|0
En .nom-fil er altså en helt enkel key/value-listing, og inneholder alt av relevant metadata for et opptak. Filnavnet indikerer opptaksjobbens unike ID og inneholder også hvilket rom opptaket skal gjøres i.
start: Start-tidspunktet oppgis i Unix-time, og trenger derfor å konverteres frem og tilbake i alle grensesnitt hvor det skal benyttes.
duration: Varighet oppgis i hele minutter.
captureagent: Oppgir hvor jobben skal kjøres.
inputs: Hvilke inn-enheter som skal benyttes. Mulige verdier: camera eller both (som i kamera og projektorbilde) - i en fremtidig versjon vil dette endres til en opplisting, da det kan tenkes at man har flere mulige inputs.
outputs: Oppgir hvorvidt noe skal lagres, strømmes eller begge deler (save, stream, both)
lecturer: Hvem er det som snakker. Her oppgis som regel en HiG-ansatts brukernavn, som så kan oversettes i grensesnittet ved hjelp av katalog-oppslag eller lignende, men det kan også benyttes fritekst hvis ønskelig.
topic: Overliggende sorteringsmulighet, for eksempel en foredragsserie eller et fag (i eksempelet er det oppgitt en HiG-fagkode, som i brukergrensesnitt oversettes til det fulle navnet på et fag), dette kan også være fritekst.
title: Tittel på opptaket/strømmen, for eksempel dagens emne(r).
description: En mer detaljert beskrivelse av hva som gås gjennom i forelesningen.
started og ended:(Ikke i bruk) mulighet for opptaksenheten å angi når en jobb faktisk ble startet og avsluttet.
Hvis det skulle komme behov for å ha mer metadata er det så enkelt som å legge til en ny linje i filen, da all programvare som håndterer denne filen ignorerer felter den ikke kjenner til.
Alle .nom-filer håndteres i en katalogstruktur som dette:
/opt/omnom/spool:
├── k102
│ ├── backlog
│ ├── capture
│ └── new
├── k105
│ ├── backlog
│ ├── capture
│ └── new
├── lille-eureka
│ ├── backlog
│ ├── capture
│ └── new
│ └── lille-eureka-3e1bebf1aaf2.nom
├── master-pool
│ ├── new
│ └── process_queue
└── store-eureka
├── backlog
├── capture
└── new
├── store-eureka-2fc3a6ec1546.nom
├── store-eureka-79a1a2356888.nom
└── store-eureka-a6a4b5d4efee.nomNye .nom-filer opprettes i katalogen master-pool/new, og alle klienter sjekker denne katalogen en gang i minuttet for å se om det ligger nye jobber som er tiltenkt seg selv. Når en opptaksenhet oppdager en ny .nom-fil som den skal forholde seg til flytter den filen til sin egen katalog i treet, hvor jobben vil ligge på vent. Denne katalogstrukturen er montert via NFS på samtlige enheter, slik at et system for datasynkronisering ikke er nødvendig. Brukergrensesnittet hvor man kan se og redigere planlagte jobber henter også sine data rett fra denne filstrukturen.

Opptaksenhetene sjekker hvert minutt sine respektive new-kataloger for å se om det ligger en opptaksjobb som skal startes. Jobben vil også startes hvis den oppdager at det ligger en jobb som skulle ha startet, da det er bedre å starte for sent enn ikke i det hele tatt. Hvis det blir oppdaget en opptaksjobb som har «gått ut på dato», altså at både start- og stopp-tidspunktet er passert vil jobben flyttes til katalogen «backlog».
All lagring av video under en opptaksjobb gjøres til opptaksenhetens lokale filsystem (ikke mot NFS-sharet), i katalogen /var/tmp/omnom/capture/. I denne katalogen legges også den tilhørende .nom-filen. På samme måte som det hvert minutt sjekkes om det er en jobb som skal startes, så sjekkes det om det er en jobb som skal stanses (når tiden i en opptaksjobb har gått ut). Da sendes det et stopp-signal til den kjørende opptaks-prosessen, som så avslutter opptaket og gjør en rask etterbehandling. Når opptaket har stoppet fullstendig signaliseres dette ved å legge en fil kalt «stopped» sammen med mediafilene og .nom-filen for opptaket.
Hvert minutt sjekkes det om det eksisterer et opptak i /var/tmp/omnom/capture som har status som ferdig (at filen «stopped» eksisterer), og om det er det så begynner filene å kopieres tilbake til NFS-sharet, denne gangen til katalogen master-pool/process_queue. Denne flyttingen gjøres via et perl-script som dobbeltsjekker at filene ikke blir skadet i overføringen: hvis noe går galt avbrytes flyttingen, og filene blir liggende på opptaksboksen.
Det er verdt å nevne noe om teknologien som benyttes for å utføre selve video- og lydopptaket på opptaksboksene. På samme måte som Matterhorn benyttes multimedierammeverket gstreamer som grunnlag. I gstreamer benytter man et konsept med såkalte pipelines, hvor man definerer ulike inputs (kamera-enheter, lydenheter) og sender dem gjennom forskjellige moduler og prosesser. Sånne gstreamer-pipelines kan fort bli veldig uoversiktlige, men hvis du har et Linux-system med gstreamer installert kan du se et meget enkelt eksempel her:
gst-launch-0.10 videotestsrc ! autovideosink

Det du gjør er å be gstreamer om å lage en testvideo (videotestsrc) og sende det direkte til et egnet avspillingsvindu (autovideosink). Man kan legge inn effekter i mellom videokilden og videovisningen:
gst-launch-0.10 videotestsrc ! warptv ! autoconvert ! autovideosink

Her sender vi videobildet først til filteret warptv, som legger en forvrengingseffekt på videoen, og så sender vi det forvrengte videosignalet gjennom filteret autoconvert som sørger for å konvertere fargerommet til noe som kan spilles av (fargerommet ble endret av effekten, det er ikke alle fargerom som passer med alle filtre, derfor trenger man ofte å konvertere fargerommene i pipelines).
Jo flere inputs og outputs man har, og jo mer man ønsker å gjøre, jo lengre og mer kompliserte blir gstreamer-pipelines. Hvis det er noe galt med rekkefølgen eller logikken, vil det ikke fungere i det hele tatt, så mye av magien i Omnom ligger i å dynamisk opprette fungerende og stabile pipelines ut fra hva man ønsker av inn- og ut-signaler. Dette gjøres i Omnom ved hjelp av et BASH-script(!) på 600 linjer.
Her er et eksempel på en komplett pipeline som generert av omnom.sh som tar bilde fra kamera og lyd fra mikrofon og lagrer det til disk (en av de enkleste oppgavene systemet har å utføre):
v4l2src device=/dev/cam ! videocrop top=64 left=16 bottom=64 right=16 \\ ! videorate ! video/x-raw-yuv,framerate=30/1 ! ffvideoscale \\ ! video/x-raw-yuv,width=736,height=414 ! queue2 \\ ! x264enc bitrate=600 tune=zerolatency ! tee name=cameraenctee \\ ! queue2 ! h264parse ! mpegtsmux name=cameratsmux \\ ! tee name=cameratstee ! queue2 ! filesink location=camera.ts alsasrc device=hw:0 ! audioconvert ! audio/x-raw-int,channels=1 \\ ! audioconvert ! audio/x-raw-int,channels=2 ! queue2 \\ ! faac bitrate=64000 ! audio/mpeg,mpegversion=4,stream-format=raw \\ ! tee name=audioenctee ! queue2 ! cameratsmux.
Hvis man skal gjøre både opptak og streaming samtidig blir pipelinen noen linjer lengre.

Tilbake på den sentrale serveren kjøres det hvert minutt en sjekk etter opptaksjobber som skal etterbehandles. Dette innebærer å konvertere filene til ferdige videofiler for strømming, opprette en mp3-fil og eventuelt generere en filmfil som kombinerer kameraopptak og skjermopptak hvis begge har vært benyttet. Når alt er klart flyttes katalogen med filene over til publiseringskatalogen.
Man vil da i et typisk eksempel ende opp med disse filene:
/opt/omnom/publish/1378289041-8f22d2f3b295/: audio.mp3 04-Sep-2013 12:11 50M camera.mp4 04-Sep-2013 14:04 522M camera.webm 04-Sep-2013 14:04 651M combined.mp4 04-Sep-2013 14:04 836M k105-8f22d2f3b295.nom 04-Sep-2013 12:04 179 screen.mp4 04-Sep-2013 14:04 410M screen.webm 04-Sep-2013 13:09 380M
Katalognavnet inneholder to elementer: den originale timestampen fra da .nom-filen ble opprettet – dette sørger for at katalogene alltid vil listes opp kronologisk – og den unike ID-en som ble generert når opptaksjobben ble opprettet. .nom-filen har også fulgt med, og fungerer nå som metadata-lagring for filene som ligger der. De primære film-filene lagres i to web-vennlige formater:
- mp4-fil med bilde i h264-format og lyd i AAC-format.
- webm-fil med bilde i vp8-format og lyd i vorbis-format.
Filen combined.mp4 inneholder de to videofilene stilt ved siden av hverandre, og genereres kun i .mp4-format, da det er meningen at opptakene skal spilles av i en dedikert player som synkront spiller av kamera- og skjermopptakene. .mp4-filen eksisterer primært for å kunne spille av opptakene på iOS-enheter hvor man kun kan spille av én film-fil om gangen. Opptaket i eksempelet er forøvrig på 1 time og 50 minutter.

En annen ting som ikke er helt på plass enda er den dedikerte avspilleren som skal spille av opptakene. For øyeblikket er det primært den kombinerte filmfilen combined.mp4 som benyttes når opptakene skal vises. Her ser vi på muligheten for å benytte Paella Engage Player.
Omnom-bruk i dag (i går?)
I dag har vi fire forelesningssaler som er satt opp for Omnom: K102, K105 og Store og Lille Eureka. Datamaskinene som står for opptakene ble i forkant av høstsemesteret 2013 oppdatert til vifteløse enheter, da vi opplevde masse mekanisk svikt på de Matterhorn-baserte opptaksenhetene i det foregående semesteret. Viftene sluttet å virke, med overoppheting og mystiske systemkrasj som resultat. De viftene som fortsatt fungerte støyet dessuten så mye at vi opplevde at forelesere slo av opptaksutstyret for å bli kvitt bråket, og da ville selvfølgelig ikke opptak kjøre.
I høstsemesteret 2013 har det blitt gjort over 130 opptak i 10 forskjellige fag fra alle skolens avdelinger. I tillegg har systemet blitt benyttet til gjesteforelesninger og konferanser, som for eksempel NISLecture. På toppen av dette har systemet blitt brukt til mye strømming uten opptak, som et alternativ til bruk av tradisjonelt videokonferanseutstyr. Dette ville ikke vært mulig i Matterhorn.
Veien videre
Det er fortsatt mange ting som står på ønskelista og som vi har på arbeidsplanen vår:
Flere rom
Det er stor etterspørsel etter Omnom i flere forelesningssaler. Vi har gjort en utredning på hva som er mulig, og noen av rommene som er etterspurt vil kreve ganske mye arbeid for å integreres med Omnom, men vi har det på blokka. C007 vil være enklest å få til, og dette blir gjort neste semester.
Bærbar enhet
Vi har begynt å drodle med muligheten for å lage en eller flere bærbare Omnom-enheter, med tanke på klasserombruk og lignende. Her planlegger vi å implementere et berøringsgrensesnitt, slik at man kan starte et opptak eller strømming med bare et par trykk på skjermen. Denne skjermen vil også vise en live-visning av kamera og skjermvisning.
Kontrollpanel
Arbeidet i forbindelse med bærbar enhet vil også gjøre det mulig for oss å lage et kontrollpanel for de faste installasjonene i forelesningssalene, med den samme muligheten for å umiddelbart starte en strømming eller opptak, og for å se hva kamera og skjerm vil vise på opptaket.
HD-oppløsning
Kameraene vi har montert i forelesningssalene i dag har to moduser: lav oppløsning og HD-oppløsning. I dag benyttes den lave oppløsningen, da det var dette Matterhorn var laget for å håndtere. Vi jobber nå med å teste ny maskinvare som vil la oss bytte kameraene over til HD-modus, noe som vil øke kvaliteten på tavle- og foreleseropptak betydelig.
Redigering av opptak
Som regel kommer ikke en forelesning skikkelig i gang før etter et par minutter, og de avsluttes gjerne en stund før opptaket er satt til å stanses. Det er mulig å gå inn og stanse et pågående opptak hvis man ønsker dette, men det er ikke en mulighet som benyttes så ofte. Dermed er det behov for å gjøre litt enkel redigering i etterkant. Dette er en litt større oppgave som vi har satt et stykke ned på prioriteringslisten, men det kan være vi får mye av dette gratis ved å ta i bruk Engage Player.
Bevegelige kameraer
Et av de oftest etterspurte funksjonene er muligheten for «motion tracking», altså at kameraet følger foreleser rundt i rommet. Her har vi et par idéer på blokka i forhold til å løse dette med ett enkelt kamera, men vi har også fått tak i navnet på en leverandør av en hylleløsning for kameraer med frittstående bevegelsessensor. Vi ser også på muligheten for forhåndsdefinerte kamerasnitt som man kan veksle mellom ved behov.
Plassering av kamera
I dagens løsning så er kameraene for opptak montert oppe på veggen et stykke bak i rommet. Dette har vist seg å ikke være helt optimalt, og det planlegges å flytte kameraene til oppunder taket, omtrent på høyde med projektorene som er montert i de ulike forelesningssalene, eventuelt litt lavere der det lar seg gjøre uten å sperre sikten fra salen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}